Master Linked List Problems Visually with GoNimbus
Understanding how to remove duplicates from a sorted linked list is a foundational interview skill.
At GoNimbus, we help you see how pointers move, why duplicates are removed, and how to explain it confidently in interviews.
🎯 Problem Overview
You are given a sorted singly linked list.
Your task is to remove duplicate nodes so that each value appears only once.
✔ The list must remain sorted
✔ No extra memory should be used
✔ The linked list must not be recreated
Remove Duplicates from Sorted List – Visualizer
The algorithm removes duplicates only when they are adjacent:
current.val == current.next.val🧠 Why This Problem Matters
This problem tests:
- Pointer manipulation
- Understanding of sorted data
- In-place list modification
- Time & space optimization
It is frequently asked as a warm-up linked list problem in coding interviews.
🔍 What You Will Learn
- How sorted order simplifies duplicate removal
- How to compare current and next nodes
- Why non-adjacent duplicates are ignored
- How to safely skip nodes without breaking the list
- How to write clean, interview-ready code
🎥 Learn with an Interactive Visualizer
Remove Duplicates – Step by Step
With the GoNimbus visualizer, you can:
- Enter a sorted linked list
- Watch the
currentpointer traverse the list - See duplicate nodes highlighted
- Observe nodes being removed visually
- Understand exactly when and why a node is skipped
No guesswork. Just clarity.
🧩 Core Logic Explained
Because the list is sorted:
- Duplicate values always appear next to each other
- We only need to compare:
current.valcurrent.next.val
If both are equal, we skip the next node.
🧪 Example Walkthrough
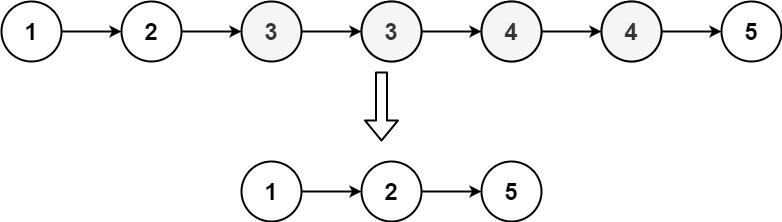
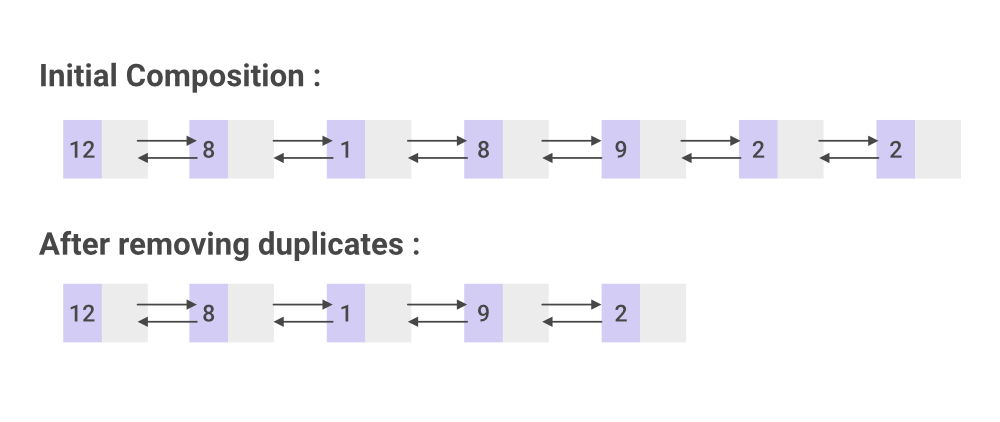
Input:1 → 1 → 2 → 3 → 3
Output:1 → 2 → 3
Explanation:
When two adjacent nodes have the same value, the duplicate node is removed by adjusting the next pointer.
Below is a clear, learner-friendly explanation with visual support, written so you can place it below the visualizer or problem statement on the GoNimbus website.
I’ve broken it into image-backed sections so learners truly see what’s happening.
🔍 Problem Recap (In Simple Words)
You are given the head of a sorted linked list.
Your task is to remove duplicate nodes so that each value appears only once, while keeping the list sorted.
📌 The key condition is: the list is already sorted.
🧠 Why “Sorted” Matters
Because the list is sorted:
- Duplicate values always appear next to each other
- You never need to search the whole list
- A single pointer traversal is enough
Example:
1 → 1 → 2 → 3 → 3
Duplicates (1 and 3) are adjacent, making them easy to remove.
👆 Core Idea (Pointer Intuition)
We use one pointer called current.
At every step:
- Compare
current.valwithcurrent.next.val - If they are equal → skip the next node
- Otherwise → move
currentforward
You never create new nodes — you just adjust pointers.
🔁 Step-by-Step Visual Walkthrough
▶ Example Input
1 → 1 → 2 → 3 → 3
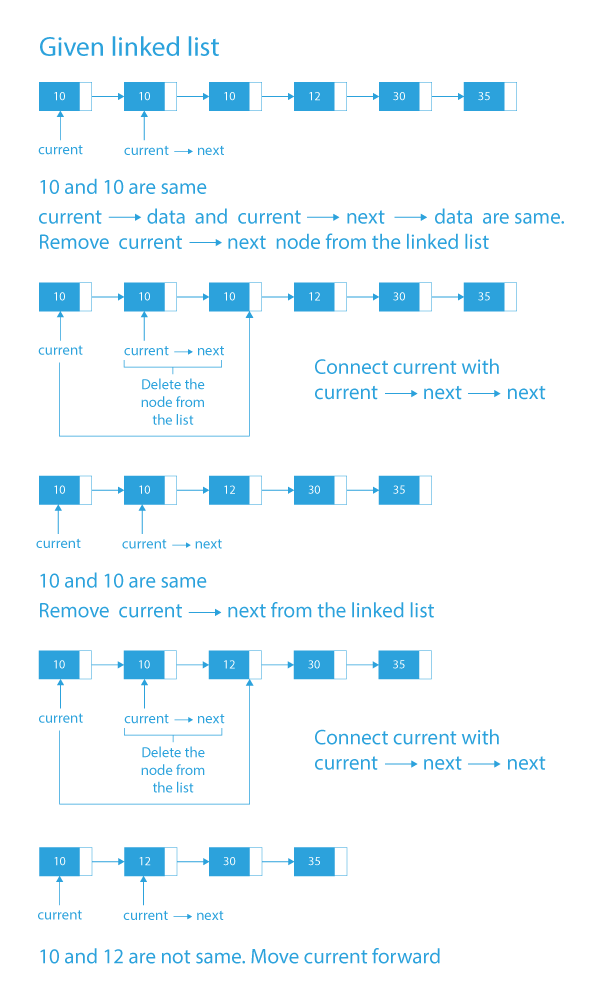
🔹 Step 1: Start at Head
current
↓
1 → 1 → 2 → 3 → 3
Compare first 1 and next 1.
🔹 Step 2: Duplicate Found
1 → (1) → 2 → 3 → 3
Values are the same → skip the duplicate node
(pointer jumps over the second 1)
🔹 Step 3: Move Forward
1 → 2 → 3 → 3
↑
current
Now 2 and 3 are different → move pointer.
🔹 Step 4: Another Duplicate
1 → 2 → 3 → (3)
Duplicate found → skip second 3.
✅ Final Result
1 → 2 → 3
All duplicates removed.
⚠ Important Clarification (Very Common Confusion)
This algorithm only removes adjacent duplicates.
❌ It will NOT work correctly if the list is not sorted.
❌ Not Sorted Example:
5 → 2 → 6 → 3 → 5
Even though 5 appears twice, they are not adjacent, so they won’t be removed.
📌 This is expected and correct behavior.
🎯 What Interviewers Look For
✔ Understanding that the list is sorted
✔ Correct pointer movement
✔ In-place modification
✔ No extra data structures
✔ Clean explanation of why it works
⏱ Complexity Analysis
- Time Complexity: O(n)
- Space Complexity: O(1)
No extra data structures are required.
⚠ Important Interview Note
This approach works only for sorted linked lists.
If the list is unsorted, a different strategy (hashing) is required.
Interviewers often test this understanding.
👩💻 Who Should Learn This?
- Beginners learning linked lists
- Students preparing for DSA interviews
- Developers revising pointer logic
- Anyone struggling with in-place list modification
🚀 Why Learn This on GoNimbus?
✔ Visual explanations, not just code
✔ Step-by-step pointer traversal
✔ Interview-ready reasoning
✔ Clean, optimized solutions
✔ Pattern-based learning
🔹 Basic Understanding (1–10)
1. What is the problem statement of “Remove Duplicates from Sorted List”?
Answer:
Given the head of a sorted linked list, remove duplicate elements so that each value appears only once and return the modified list.
2. Why is sorting important in this problem?
Answer:
Sorting ensures that duplicate values are adjacent, allowing easy comparison between current and next nodes.
3. Can this problem be solved without extra memory?
Answer:
Yes, it can be solved in-place using pointer manipulation with O(1) extra space.
4. What type of linked list is used?
Answer:
A singly linked list.
5. What does “in-place” mean here?
Answer:
The original linked list is modified without creating a new list.
6. What happens if the list is empty?
Answer:
Return null.
7. What happens if the list has only one node?
Answer:
Return the same node because no duplicates exist.
8. Do we remove all occurrences of duplicates?
Answer:
No, we keep one occurrence and remove the rest.
9. What is the expected output order?
Answer:
The list remains sorted and in original order.
10. Is recursion required?
Answer:
No, an iterative approach is preferred.
🔹 Pointer & Traversal Logic (11–25)
11. Which pointer is mainly used?
Answer:
A single pointer, usually named current.
12. What condition detects a duplicate?
Answer:current.val == current.next.val
13. How is a duplicate removed?
Answer:
By updating the pointer:current.next = current.next.next
14. When do we move the pointer forward?
Answer:
Only when the current and next values are different.
15. Why don’t we move the pointer when a duplicate is found?
Answer:
Because the new next node may still be a duplicate.
16. How many times do we traverse the list?
Answer:
Only once.
17. What is the loop condition?
Answer:while current != null && current.next != null
18. What happens if duplicates appear more than twice?
Answer:
The loop continues removing duplicates until only one remains.
19. Does this algorithm modify node values?
Answer:
No, it only changes pointers.
20. Is head ever changed?
Answer:
No, the head remains the same.
21. What happens to removed nodes?
Answer:
They are skipped and eventually garbage-collected.
22. Why is a single pointer sufficient?
Answer:
Because the list is sorted, comparisons are always local.
23. Can we use two pointers?
Answer:
Yes, but it’s unnecessary for this problem.
24. Is tail pointer needed?
Answer:
No.
25. Why not use a HashSet?
Answer:
Because sorting removes the need for extra memory.
🔹 Complexity & Optimization (26–35)
26. What is the time complexity?
Answer:O(n), where n is the number of nodes.
27. What is the space complexity?
Answer:O(1) extra space.
28. Is this the optimal solution?
Answer:
Yes, both time and space optimal.
29. Can recursion cause stack overflow?
Answer:
Yes, for very large lists.
30. Why is iteration preferred?
Answer:
It avoids recursion overhead.
31. Is the problem suitable for beginners?
Answer:
Yes, it teaches basic pointer manipulation.
32. Can this approach work on unsorted lists?
Answer:
No, it relies on sorted order.
33. What would you do for an unsorted list?
Answer:
Use a HashSet or sort the list first.
34. Is stable ordering preserved?
Answer:
Yes.
35. Does this violate the “Do not modify input” rule?
Answer:
No, modification is expected.
🔹 Edge Cases & Variations (36–45)
36. What if all elements are the same?
Answer:
The result will contain only one node.
37. What if there are no duplicates?
Answer:
The list remains unchanged.
38. Can negative values exist?
Answer:
Yes, value range does not affect logic.
39. Does node index matter?
Answer:
No, only values matter.
40. What if the list contains one duplicate at the end?
Answer:
It will be removed correctly.
41. Can this be applied to doubly linked lists?
Answer:
Yes, but next pointer logic remains the same.
42. What if the list is circular?
Answer:
This algorithm will fail without cycle handling.
43. How to detect incorrect input?
Answer:
If the list is not sorted, output may be wrong.
44. Is this problem related to real-world use cases?
Answer:
Yes, removing duplicate records in ordered datasets.
45. Can this logic be visualized?
Answer:
Yes, step-by-step node comparison visualizers are ideal.
🔹 Interview-Oriented Advanced Questions (46–55)
46. What invariant is maintained?
Answer:
All nodes before current are unique.
47. How would you explain this to a beginner?
Answer:
Compare each node with the next and skip duplicates.
48. How is this different from “Remove Duplicates II”?
Answer:
That problem removes all occurrences of duplicates.
49. Can this be solved using recursion?
Answer:
Yes, but it’s less efficient.
50. What makes this problem important in interviews?
Answer:
It tests linked list traversal, pointer logic, and constraints usage.
51. Can this be implemented in one line?
Answer:
No, pointer updates require condition checks.
52. Is memory allocation involved?
Answer:
No new nodes are created.
53. How would you debug this?
Answer:
Print node values during traversal.
54. What mistake do beginners make?
Answer:
Moving the pointer even when a duplicate is found.
55. What is the key takeaway?
Answer:
Sorted structure simplifies duplicate removal using pointer manipulation.
🔗 Start Learning Today
Don’t memorize solutions.
Understand how linked lists work.
👉 Try the Remove Duplicates Visualizer
👉 Build strong pointer intuition
👉 Crack linked list interview questions with confidence